Tire树(字典树)入门

Tire树(字典树)入门
MOOC后台第二次算法授课
0.写在前面
这一次讲一些涉及数据结构的东西…想来想去还是要讲一些实用的算法,所以选择了字典树…不过字典树我也只是略知一二,而且已经有快三个月没碰了,所以写这篇文章也是我对字典树的一个复习和总结。
学习字典树当然要懂树这种数据结构。这里主要用数组的形式存树,优点是效率较高且便于理解。
1. 字典树简介
1.1 关于树
已经了解树这种数据结构的可以直接跳过~
1.1.1 什么是树
树是一种优雅且高效的数据结构。直观地看,它是数据元素(在树中称为结点)按分支关系组织起来的结构,很象自然界中的树那样。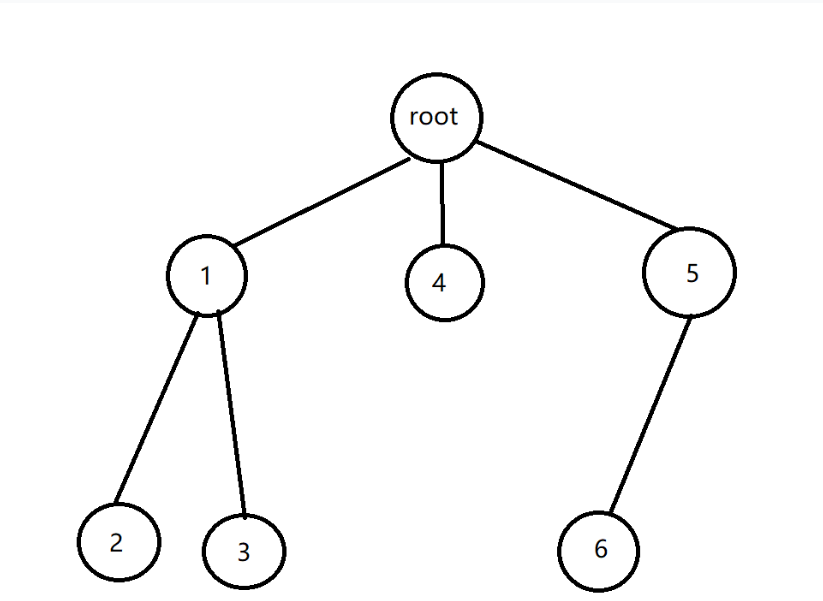
树结构在客观世界中广泛存在,如人类社会的族谱和各种社会组织机构都可用树形象表示。树在计算机领域中也得到广泛应用,如在编译源程序如下时,可用树表示源源程序如下的语法结构。又如在数据库系统中,树型结构也是信息的重要组织形式之一。一切具有层次关系的问题都可用树来描述。(摘自百度百科)
1.1.2 相关定义
一棵树(tree)是由n(n>0)个元素组成的有限集合,其中:
(1)每个元素称为结点(node);
(2)有一个特定的结点,称为根结点或根(root);
(3)除根结点外,其余结点被分成m(m>=0)个互不相交的有限集合,而每个子集又都是一棵树(称为原树的子树)
1.1.3 树的表示
有很多种用来表示树的方法,可以在数据结构书上学习。这里就讲一个最简单的数组表示法。字典树的实现也主要使用这种方法。
定义二维数组root[i][j] = k,表示ID为i的结点的第j个儿子的ID为k。
1.2 关于字典树
字典树是一种树状结构,它可以解决词频统计、前缀是否重复等问题。同时它也是AC自动机的基础。它典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
为了直观,先举个例子。下图是对字符串”acm”,”apple”,”ape”,”cat”,”cap”,”pixel”建立的一棵字典树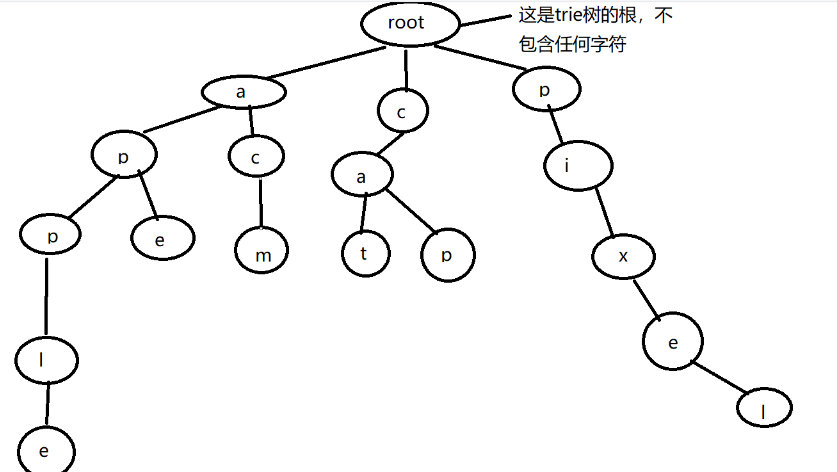
字典树的性质:
- 根结点不包含字符,除根节点外的每个结点都只包含一个字符
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符串不相同。
字典树的应用
- 查询某个前缀在字符表中是否存在
- 统计某个字符串前缀出现次数
2.字典树实现
2.1 字典树的表示
字典树一般有两种表示方式。一种通过结构体+指针,一种通过数组。
1.结构体+指针表示法
typedef struct Trie_node
{
int count; // 统计单词前缀出现的次数
struct Trie_node* next[26]; // 指向各个子树的指针
bool exist; // 标记该结点处是否构成单词
}TrieNode , *Trie;
2.数组表示法
//我们设数组trie[i][j]=k,表示编号为i的节点的第j个孩子是编号为k的节点。
const int MAXN = 1000; //树的结点数量
int trie[MAXN][26]; //每个结点最多有26个儿子,代表a~z 26个字母,如果还需要保存大写字母,空间应该开到52
int count[MAXN]; //记录以每个结点为结尾的前缀出现次数
bool exist[MAXN]; //记录每个结点是否构成单词
两种方法都是可行的,由于数组表示简单粗暴效率高,而且销毁容易,本文都使用数组表示法。
2.2 操作
字典树一般有插入和查找两种操作。
这里我们用下图作为例子,解释一下如何维护一棵字典树。
这是一棵已经插入”apple”,”ape”,”cat”三个字符串的树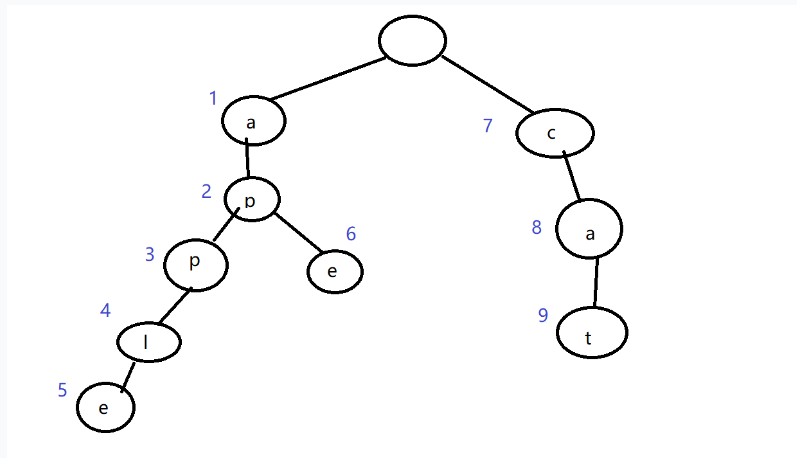
这里提一下结点”ID”与结点的”值”的区别。
如图,蓝色标注的是当前结点的ID,圈内的为当前结点的值。
每次我们给树新增一个结点时,都会给它分配一个ID,我们保证每个结点的ID都不相同。访问结点是通过ID访问的。
值表示当前结点存储的字符,对于一棵树来说值是可以相同的。
2.2.1插入操作
字典树一开始是一棵只有根结点的空树,它将所有字符串保存在除了根之外的结点之中。根节点的ID为0。
现在我们要为其插入”apple”字符串,步骤如下:
检查根结点是否有值为’a’的子结点,发现不存在,于是给根结点插入值为’a’的子结点,分配ID为1
检查ID为1的结点是否存在值为’p’的结点,发现不存在,该结点插入值为’p’的子结点,分配ID为2
循环上述步骤,直到字符串的最后一个字符’e’插入到树中,操作结束。
我们可以看出,插入操作就是把一个字符串分为一个个字符,将字符一个个插入到树之中去。
我们如果想继续插入字符串”ape”的话,和上述步骤相似。
检查根结点是否有值为’a’的子结点,发现存在,ID为1,进入该结点
检查ID为1的结点是否有值为’p’的子结点,发现存在,ID为2,进入该结点
检查ID为2的结点是否有值为’e’的子结点,发现不存在,给该节点插入值为’e’的子结点,分配ID为3
代码实现
int tot; //全局变量,用于给各个结点分配ID
void insert(string str) //待插入的字符串为str
{
int len = str.length(); //获得待插入单词的长度
int rt = 0; //从根出发
for(int i=0;i<len;i++)
{
int k = str[i] - 'a';
if(!trie[rt][k]) //如果该结点的子结点不存在
{
trie[rt][k] = ++tot; //给新的结点编号
}
//exist[rt] = true 单词结束的标记
rt = trie[rt][k]; //向下延伸
}
}
2.2.2查找操作
查找有很多种,可以查找前缀也可以查找整个单词。
这里以查找前缀是否出现过为例。
查找操作很好理解,与插入操作类似,对于待查找的字符串前缀str,我们也将他分为一个个字母。从根开始一个个字母往下找,如果可以沿着树的某条路径一直走到str的结尾,说明这个前缀存在。
代码实现
bool search(string str)
{
int len = str.length();
int rt = 0;
for(i=0;i<len;i++)
{
int k = str[i] - 'a';
if(!trie[rt][k])
{
return false; //无法向下走下去了,说明没有这个前缀
}
rt = trie[rt][k];
}
return true; //走到单词末尾了,说明查找到了
}
2.3 实战
有插入和查找两个操作就可以解决绝大部分问题了,这里举个最简单的例子。
给出六个字符串: apple,acm,ape,cat,cap,pixel 和n个询问,每个询问给出一个字符串s,输出以s为前缀的字符串有几个。
样例输入
ap
样例输出
2
总而言之,就是插入操作和查询操作的运用。我们新建一个统计数组cnt[MAXN],记录每个结点被访问到的次数。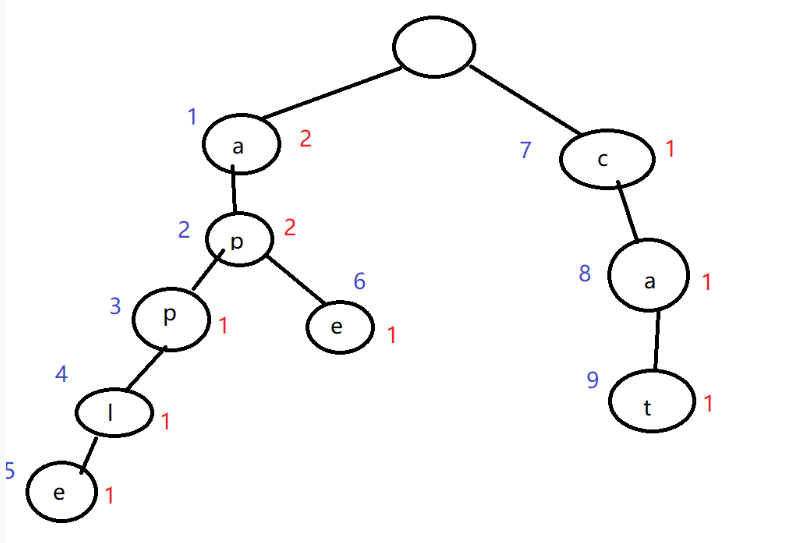
如图,红色标记的数字即为每个结点的cnt值
#include<iostream>
#include<cstring>
#include<string>
using namespace std;
const int maxn = 1000;
int tot;
int trie[maxn][26],cnt[maxn];
void insert(string str)
{
int len = str.length();
int rt = 0;
for(int i=0;i<len;i++)
{
int k = str[i] - 'a';
if(!trie[rt][k])
{
trie[rt][k] = ++tot;
}
rt = trie[rt][k]; //往下走
cnt[rt]++; //该结点计数+1
}
}
int search(string str)
{
int len = str.length();
int rt = 0;
for(int i=0;i<len;i++)
{
int k = str[i] - 'a';
if(!trie[rt][k]) return 0; //这样的前缀不存在
rt = trie[rt][k];
}
return cnt[rt]; //返回这样的前缀出现的次数
}
void init() //对字典树的初始化
{
insert("apple");
insert("ape");
insert("acm");
insert("cat");
insert("cap");
insert("pixel");
}
int main()
{
int n;
string str;
init();
cin >> n;
while(n--)
{
cin >> str;
cout << search(str) << endl;
}
}
测试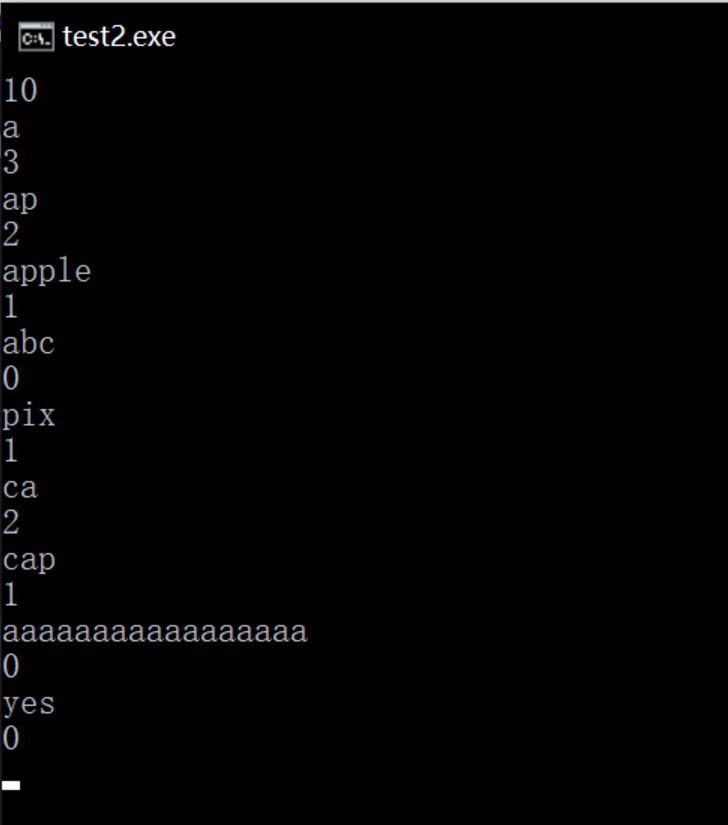
3.例题
1.HDU1251 统计难题
求前缀出现次数,字典树模板题,和我上面举的例子差不多。
2.HDU1075 What Are You Talking About
先给出一些单词的密码形式,然后给出一串密码,将它翻译成原文。
这里就不是判断前缀是否出现了,而是判断整个单词是否出现过。解决方案是建立exist数组,每次插入字符串时,在字符串结尾的那个字符的结点上做一个特殊标记,表示该节点是某个单词的结尾。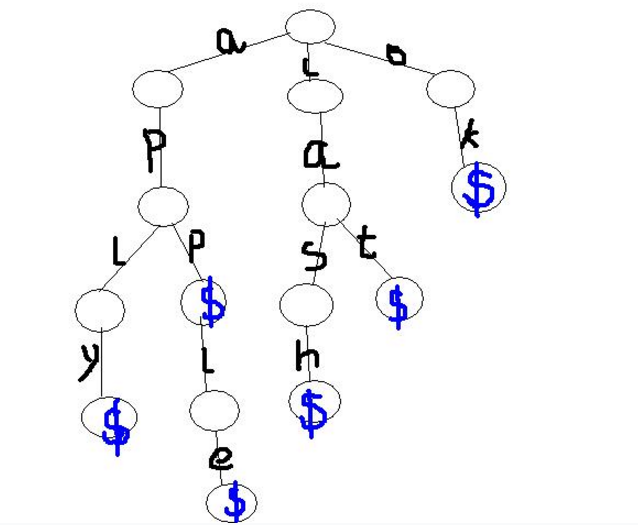
如图,在每个单词的结尾做特殊标记。
在查询操作时,若一直向下找,最后一个结点有特殊标记,说明该单词存在。
/*这里用的是结构体+指针的方法存树,你们可以学习一个*/
#include <iostream>
#include <cstdio>
#include <cstring>
#include<malloc.h>
using namespace std;
struct node
{
char *cc;//用来存最后一个单词
node *next[26];
int flag;//用来标记
node()//初始化
{
for (int i=0; i<26; i++)
{
next[i]=NULL;
}
flag=0;
}
};
node *p,*root=new node();
void insert(char *s,char *t)//对火星文进行建树,在最后一个字符下面存下对应的英文字符串
{
p=root;
for (int i=0; s[i]!='\0'; i++)
{
int k=s[i]-'a';
if (p->next[k]==NULL)
p->next[k]=new node();
p=p->next[k];
}
p->flag=1;//用来标记当前火星字符串的结尾有对应的英文字符串
p->cc=(char*)malloc((strlen(t)+1)*sizeof(char));//申请动态空间
strcpy(p->cc,t);//将对应字符串存下
}
void Search(char *s)
{
p=root;
if(strlen(s)==0)
return ;
for (int i=0; s[i]!='\0'; i++)
{
int k=s[i]-'a';
if (p->next[k]==NULL)
{
printf("%s",s);//把原有字母输出(寻找的字符串不存在的,也就是未全部找完)
return;
}
p=p->next[k];
}
if (p->flag)
printf ("%s",p->cc);//输出找到的对应的单词
else
printf ("%s",s);//特殊判断找不到的情况,把原有字母输出(全部找完仍没有对应的)
}
int main()
{
char str[15],ch1[3010],ch2[3010];
char ch[3010];
scanf("%s",&str);
while (~scanf("%s",&ch1))
{
if (strcmp(ch1,"END")!=0)
{
scanf("%s",&ch2);
insert(ch2,ch1);
}
else
break;
}
scanf("%s",&str);
getchar();
while (gets(ch1))
{
if (strcmp(ch1,"END")==0)
break;
int k=0;
// cout<<111111111<<endl;
for(int i=0; ch1[i]!='\0'; i++)
{
if(ch1[i]>'z'||ch1[i]<'a')//将需要判断的字符串分割成一小部分一小部分
{
//cout<<"333333"<<ch1[i]<<endl;
ch[k]='\0';//找到一个就断开
Search(ch);//寻找相应的对应单词
printf("%c",ch1[i]);//输出断点的字符
k=0;//覆盖已经找过的字符,从头一个个存下来
}
else
{
ch[k++]=ch1[i];// 将符合条件的字符存下来
}
}
printf("\n");
}
return 0;
}
4.写在结尾
字典树这个坑很久没填了,今天终于好好写了一下。
参考了这两篇文章
知道没几个人会看到这里….怎么说也是对自己的一个总结吧..Acm玩着也挺累的,集训队各个都是神仙,深刻体会到自己的弱。学了大半年,感觉和大佬差距不是一点点大。再努把力,跟不上大佬们就认命吧,毕竟学业也挺忙……